
- 1. TypeScript Express tutorial #1. Middleware, routing, and controllers
- 2. TypeScript Express tutorial #2. MongoDB, models and environment variables
- 3. TypeScript Express tutorial #3. Error handling and validating incoming data
- 4. TypeScript Express tutorial #4. Registering users and authenticating with JWT
- 5. TypeScript Express tutorial #5. MongoDB relationships between documents
- 6. TypeScript Express tutorial #6. Basic data processing with MongoDB aggregation
- 7. TypeScript Express tutorial #7. Relational databases with Postgres and TypeORM
- 8. TypeScript Express tutorial #8. Types of relationships with Postgres and TypeORM
- 9. TypeScript Express tutorial #9. The basics of migrations using TypeORM and Postgres
- 10. TypeScript Express tutorial #10. Testing Express applications
- 11. TypeScript Express tutorial #11. Node.js Two-Factor Authentication
- 12. TypeScript Express tutorial #12. Creating a CI/CD pipeline with Travis and Heroku
- 13. TypeScript Express tutorial #13. Using Mongoose virtuals to populate documents
- 14. TypeScript Express tutorial #14. Code optimization with Mongoose Lean Queries
- 15. TypeScript Express tutorial #15. Using PUT vs PATCH in MongoDB with Mongoose
With MongoDB aggregation, we can process data and get computed results. Thanks to that, we get additional information about the documents in our collections. You can use it to perform some tasks on the data and let the MongoDB handle it for you. In this article, we create an endpoint that gives us a report about the users of our application.
As always, the code is in the express-typescript repository.
MongoDB aggregation
The MongoDB database contains a mechanism called the MongoDB aggregation framework. It is working with the concepts of data processing pipelines. Documents enter a multi-stage pipeline that can transform them and output the aggregated result.
Since there might be multiple stages, we pass an array to the aggregate function. Every element of that array is an object that has a property naming one of the possible stages that you can use. For example:
|
1 2 3 4 5 6 7 8 9 |
const arrayOfJohns = await this.user.aggregate( [ { $match: { name: 'John', }, }, ], ); |
Using $match works similarly to the find function.
The output of a stage is later passed to the next stage in the array if there are any.
$group
The $group stage groups documents by some expression. This process creates a document per group. The MongoDB aggregation framework groups data based on the id that we set up for those documents:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 |
import * as express from 'express'; import Controller from '../interfaces/controller.interface'; import userModel from '../user/user.model'; class ReportController implements Controller { public path = '/report'; public router = express.Router(); private user = userModel; constructor() { this.initializeRoutes(); } private initializeRoutes() { this.router.get(`${this.path}`, this.generateReport); } private generateReport = async (request: express.Request, response: express.Response, next: express.NextFunction) => { const usersByCountries = await this.user.aggregate( [ { $group: { _id: { country: '$address.country', }, }, }, ] ); response.send({ usersByCountries }); } } export default ReportController; |
In the example above the users are grouped based on the countries they live in. You can group based on multiple properties. To do that, add them to the _id object.
Please note that to access the original document we need to use an expression beginning with a dollar sign.
In this example, we use '$address.country'.

There are two issues with that result. The first one is that it includes people that have no country saved at all. We can fix that by adding an additional stage to the pipeline.
Combining multiple stages
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
const usersByCountries = await this.user.aggregate( [ { $match: { 'address.country': { $exists: true, }, }, }, { $group: { _id: { country: '$address.country', }, }, }, ] ); |
In that example, before grouping users, we first make sure to filter out all users without the needed data. To do this, we use an operator called $exists. Throughout this article, we get a chance to use other operators too.
The second issue is that there is no actual users data in the return value. To fix it, we need to acknowledge the fact that we can assign more properties to grouped documents aside from _id. The catch is that they need to use accumulator operators.
An example of such is the $sum. It returns a sum of numerical values. Let’s use it to count all our users in a particular country:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
const usersByCountries = await this.user.aggregate( [ { $match: { 'address.country': { $exists: true, }, }, }, { $group: { _id: { country: '$address.country', }, count: { $sum: 1, } }, }, ] ); |
To understand how it works we need to notice that the $sum accumulation runs for each document in a group. Since we want a number of people in a group, for each person we add 1 to the result. If users would have their age in their documents, writing $sum: '$age' would have given a sum of the age of all users in a group.
The accumulator operator that we need here is called $push. It returns an array of values that were grouped. In our case: users.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
const usersByCountries = await this.user.aggregate( [ { $match: { 'address.country': { $exists: true, }, }, }, { $group: { _id: { country: '$address.country', }, users: { $push: { name: '$name', _id: '$_id', }, }, count: { $sum: 1, } }, }, ] ); |
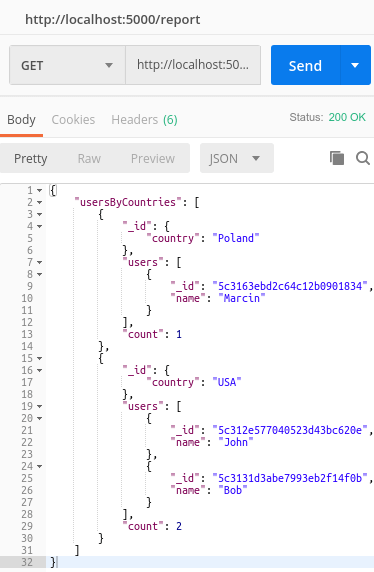
Within the $push accumulator operator, we need to write down every field that we want to appear in the output. One of them can be _id and we can use it in another stage of the accumulator pipeline.
$lookup
In the $lookup stage we perform a join. It means that we can attach other documents to existing ones based on a field. A very similar thing happens, when in the previous part of the tutorial we use the populate function. For example, we can use $lookup to attach whole user documents based on the array with _id we got in the $group stage. It works thanks to the fact that since MongoDB 3.3.4 we can perform $lookup directly on arrays.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
const usersByCountries = await this.user.aggregate( [ { $match: { 'address.country': { $exists: true, }, }, }, { $group: { _id: { country: '$address.country', }, users: { $push: { _id: '$_id', }, }, count: { $sum: 1, } }, }, { $lookup: { from: 'users', localField: 'users._id', foreignField: '_id', as: 'users', } } ] ); |
The $lookup syntax is as follows:
- from: it specifies the collection in the database to perform the join with
- localField: it is the field from our existing document that we want to look for in the collection
- foreignField: it is a field in the collection specified in the “from” collection
- as: the name of the property holding the result. If there are multiple results, it is an array.
In the example above, we first filter out every user that does not have the country specified. Then, we group them based on their country and finally, we look up all of their data in the database.
Please note that the $lookup stage needs some time to finish. In the example above we can manage without using it by simply writing down all of the fields that we need in the $push stage.
Another example is to fetch all articles written by users from a particular country. To do that we can perform a $lookup like that:
|
1 2 3 4 5 6 7 8 |
{ $lookup: { from: 'posts', localField: 'users._id', foreignField: 'author', as: 'articles', } } |
The above aggregation adds a field articles to our groups that are written by people from the “users” array.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
{ "_id": { "country": "Poland" }, "users": [ { "_id": "5c3163ebd2c64c12b0901834", "name": "Marcin" } ], "count": 1, "articles": [ { "_id": "5c3215545ed1b14df7468ed3", "title": "Lorem ipsum", "content": "Dolor sit amet", "author": "5c3163ebd2c64c12b0901834", "__v": 0 } ] } |
$addFields and $sort
Next useful type of stage is $sort. It allows us to sort all documents based on specified numerical fields. For example to sort the countries by the number of users:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
{ $group: { _id: { country: '$address.country', }, users: { $push: { _id: '$_id', name: '$name', }, }, count: { $sum: 1, }, }, }, { $sort: { count: 1, }, } |
- count: 1 results in ascending order
- count: -1 specifies a descending order
In the example above we sort based on a field that we added in a previous stage. Let’s go a bit further and use the $addField stage to sort by the country in which users wrote the most amount of articles. Thanks to it, and the $size operator, we can add a field that holds the length of the articles array:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 |
const usersByCountries = await this.user.aggregate( [ { $match: { 'address.country': { $exists: true, }, }, }, { $group: { _id: { country: '$address.country', }, users: { $push: { _id: '$_id', name: '$name', }, }, count: { $sum: 1, }, }, }, { $lookup: { from: 'posts', localField: 'users._id', foreignField: 'author', as: 'articles', }, }, { $addFields: { amountOfArticles: { $size: '$articles' }, }, }, { $sort: { amountOfArticles: 1, }, }, ], ); |
There are a lot more possible MongoDB aggregation pipeline stages. Hopefully, with those basics, you can use any of them with the help of documentation.
Aggregating using different functions
Aside from a generic aggregate function, we have a set of functions that we can use to perform MongoDB aggregation with Mongoose.
countDocuments
The countDocuments function counts the number of documents matching a provided filter. It is very similar to the count function that is now deprecated. A very similar example is to get the number of users from a certain country.
|
1 2 |
const numberOfUsersFromUSA = await this.user.countDocuments({ address: { country: 'USA' } }); response.send({ numberOfUsersFromUSA }); |
To make it a bit more complex, let’s count the users that provided the address. To do that, we need to use more advanced features instead of a simple filter object that we pass to the countDocuments function. We can do it with the usage of operators.
We can perform that calculation using the $exists operator:
|
1 2 3 4 5 6 7 |
const numberOfUsersWithAddress = await this.user.countDocuments( { address: { $exists: true, } } ); |
distinct
The distinct function finds distinct values for a specified field across a collection. It returns the results in an array. We use it to return all of the countries that our users live in:
|
1 |
const countries = await this.user.distinct('address.country'); |
In the simple example above we passed a string containing the name of the field that we want to find.
As you can see, it can also be a nested property, To find it, we use a simple object notation with a dot. We can also pass an object with conditions for a more complex example where we look for the countries in which the users of Gmail live. We use another handy operator here, which is $regex.
|
1 2 3 4 5 |
const countries = await this.user.distinct('address.country', { email: { $regex: /@gmail.com$/ } }); |
If you would like to know more about regular expressions and how to use them in JavaScript, check out my Regex course.
Summary
In this article, we covered the basics of processing data with the MongoDB aggregation framework. Using it, we created the /reports endpoint that gives us additional information about our application and its users. With the knowledge of how does $group, $lookup, and $addField work, we grasped the concept of what are aggregation pipeline stages and how to use them with both simple queries and more complex ones using operators like $regex and $sum.
